flume拦截器 保留binlog es、data、database、table、type字段 分区字段名称: eventDate 放入 /opt/cloudera/parcels/CDH/lib/flume-ng/lib目录重启flume即可
”大数据 flume 拦截器 binlog“ 的搜索结果
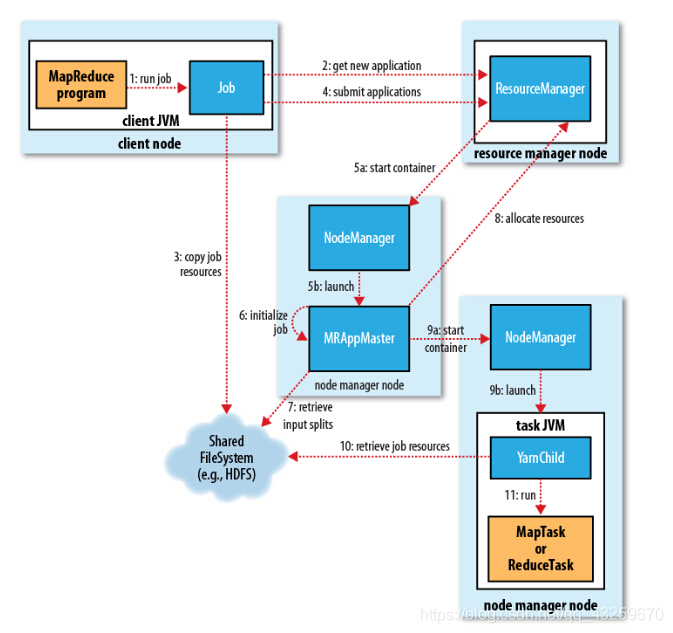
目录Flume版本选择项目流程Flume核心配置启动flume agent采集数据思考问题 hdfs路径是否正确flume自定义拦截器 Flume版本选择 Flume 1.6 无论是Spooling Directory Source和Exec Source均不能满足动态实时收集的...

flume采集数据源为lo日志
大数据八股文(自用)
标签: 大数据
实现的逻辑是继承GenericUDF,重写evaluate方法,getdisplay方法。打包上传到hdfs路径上或者hive的lib目录 注册自定义的函数UDTF炸裂 一行多输出 TUDAF聚合多行输出一行Aggregate前台是和用户直接交互的界面和各种...
多线程是指程序中包含多个执行流,即一个程序中可以同时运行多个不同的线程来执行不同的任务。优点:可以提高cpu的利用率。多线程中,一个线程必须等待的时候,cpu可以运行其它的线程而不是等待,这样大大提高了程序...
你。

紧接上一篇点击前往数仓准备工作电商的业务流程可以以一个普通用户的浏览足迹为例进行说明,用户点开电商首页开始浏览,可能会通过分类查询也可能通过全文搜索寻找自己中意的商品,这些商品都是存储在后台的管理系统...
1)基本介绍金山云2.21号下午4点:电话面试部门主要是做数据平台,...(4)Flume如何保证数据不丢;TailDir如何保证数据完整性;记不清了,是读取一个Postion(5)Flink如何保证exactly-once语义; Flink和Spark的区别
某司出行大数据 1、项目概述 随着人们对出行的需求日益增加,出行的安全问题,出行的便捷问题等问题日益突出,特别是安全出行是我们每个人都迫切需要的,为了增加出行的编辑,提高出行的安全,对我们乘车的细节...
大数据知识详解
1.Maxwell是由美国Zendesk公司开源,使用Java编写的MySQL变更数据抓取软件。他会实时监控Mysql数据库的数据变更操作(包括insert、update、delete),并将变更数据以JSON的格式发送给Kafka、Kinesi等流数据处理平台...

套路:从body中拿出采集到的数据,解析出有用字段放入header中,配置文件中可以获取header中的东西。作用1:把从Kafka中获取的json串的业务表名放到header中。作用2:把从Kafka中获取的json串的ts时间戳转换成毫秒,...

Kafka接收MySQL BinLog日志,同一个表的同一个主键需要按照顺序来消费。 如果数据一条数据实际顺序是先create,再delete,消费是也必须按照这个顺序。 但是kafka只保证了同一分区内的数据是有序的。 所以需要将同一个...
数据仓库数据同步策略
大数据复习 概念 巨量数据集合,指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。 ...
大数据知识点总结 mr 工作原理 ☆☆☆☆ split 机制 ☆☆☆☆☆ namenode,datanode,secondaryNameNode分别是干什么的?☆☆☆☆☆ mr on yarn 工作原理 ☆☆☆☆☆ fsimage 和 edits 是干什么的?为什么要使用?☆...
离线阶段 刚去公司的时候,做数据的迁移,写sqoop脚本,(注意:这里可能会问到sqoop增量导入数据的方式式,一般会用到append追加的模式)把数据从oracle数据库导入到hive当中(注意: a.这里我们使用是shell...


大数据自学笔记——电商数仓5.0搭建学习笔记


物流数仓的数据采集,主要用到了DataX做全量同步,Flink-CDC做增量同步
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地